Czym są narzędzia SI (sztucznej inteligencji) i czemu chcemy weryfikować ich używanie?
Narzędzia do automatycznego generowania tekstu są oprogramowaniem, które wykorzystuje sztuczną inteligencję. Podstawą ich działania są algorytmy uczenia maszynowego, które podlegają trenowaniu na ogromnych zbiorach danych. Dzięki temu, takie narzędzia są zdolne do tego, żeby się uczyć i nieprzerwanie doskonalić wzory i reguły, na których się opiera. Tekst wygenerowany przez takie narzędzia, jest podobny do tekstu napisanego przez człowieka. W zależności od tego, jak dobrze wyuczony jest algorytm, taki wygenerowany tekst może być prawdziwy lub zawierać błędne informacje.
Narzędzia tego typu mogą służyć do generowania przeróżnych tekstów (m.in. marketingowych, naukowych, literackich).
Jakie są zagrożenia i możliwości użycia narzędzi typu SI?
Narzędzia do automatycznego generowania tekstu są coraz bardziej popularne ze względu na łatwość w obsłudze i możliwości, które oferują. Korzystanie z pomocy maszyn przy pisaniu tekstów, w szczególności jako pomoc przy poprawie jakości i poprawności treści zwiększa zapotrzebowanie na takie programy. Generowanie tekstów w narzędziach sztucznej inteligencji może zwiększać produktywność i kreatywność użytkowników.
Zdarzają się jednak próby generowania całości tekstu, a niektóre osoby podpisują się pod taką pracą swoim nazwiskiem. Takie działanie może słusznie wzbudzać kontrowersje, szczególnie gdy spojrzymy na rosnącą popularność tego typu niewłaściwych praktyk.
Stworzenie narzędzia, które by wskazywało czy autor tekstu korzystał lub nie ze sztucznej inteligencji, jest aktualnie praktycznie niemożliwe. Aby takie rozwiązanie mogło zaistnieć, należałoby z większą dokładnością identyfikować wszystkie charakterystyczne cechy tekstu napisanego przez człowieka oraz cechy tekstu wygenerowanego przy użyciu narzędzi sztucznej inteligencji.
Jedną z przeszkód do stworzenia tak dokładnego narzędzia jest stałe rozwijanie modeli, na których opierają się generatory tekstów. Kolejnym problemem jest to, że zarówno tekst generowany przez SI może być realistyczny i trudny do odróżnienia od tekstu naturalnego, jak również tekst naturalny może posiadać cechy wygenerowane automatycznie (np. definicje, reguły, schematy).
Wszystkie narzędzia, które służą identyfikacji automatycznie wygenerowanego tekstu, mają swój margines błędu, w ramach którego mogą wystąpić fałszywie pozytywne wskazania oraz fałszywie negatywne. Osoby korzystające z narzędzi rozpoznawania SI muszą mieć tego świadomość.
Jakie założenia w JSA przyjęliśmy tworząc proponowane rozwiązanie?
Metoda podstawowa
JSA w swoim rozwiązaniu opiera się o model językowy, który wyznacza pewne prawdopodobieństwo dla następujących po sobie wyrazów i fraz językowych, ze względu na dany kontekst. Np. wyrażenie szybko będzie miało wyższe prawdopodobieństwo wystąpienia w kontekście biegnie _____ niż wyrażenie głośno. Każdy tekst jest analizowany pod kątem tego właśnie prawdopodobieństwa. Poziom prawdopodobieństwa kolejnych składowych tekstu określany jest algorytmem.
Pierwsza iteracja
Narzędzie wdrożone do JSA w pierwszej iteracji wykorzystuje model językowy, który przybliżający prawdopodobieństwo wyrażeń języka ze względu na dany kontekst. Model ten jest przeszkolony na dużym zbiorze danych tekstowych.
W systemie przyjmujemy proste kryterium klasyfikacji, w którym dany fragment tekstu jest klasyfikowany jako podejrzany, gdy jego wartość Perplexity jest mniejsza niż zadana wartość progowa. Jako podejrzany rozumiemy więc fragment tekstu, który ma duże prawdopodobieństwo wygenerowania przez model językowy w takiej formie.
Specyfika false negative-false positive
Rozumienie fałszywych pozytywów i fałszywych negatywów w możliwościach wykrywania użycia sztucznej inteligencji
W przypadku każdego programu czy funkcjonalności aplikacji należy mieć świadomość tzw. fałszywych pozytywów i fałszywych negatywów.
- Fałszywym pozytywem (FP) określane jest niepoprawne zidentyfikowanie tekstu lub jego fragmentu, jako wygenerowanego przez sztuczną inteligencję
- Fałszywym negatywem (FN) można określić taki fragment tekstu, który mylnie został potraktowany jako napisany przez człowieka.
Z punktu widzenia systemu antyplagiatowego fałszywe negatywy mogą mieć konsekwencje w postaci niewykrycia tekstu wygenerowanego automatycznie, co może skutkować manipulacjami i przywłaszczaniem sobie treści nie swojego autorstwa. Fałszywe pozytywy mogą skutkować błędnym posądzaniem o złą wolę, co dalej może utrudniać proces dyplomowy.
Można wymienić kilka czynników, które przyczyniają się do błędów w klasyfikacji. Jednym z nich jest to, że narzędzia, które korzystają ze sztucznej inteligencji są nieustannie udoskonalane i uczone, aby lepiej odzwierciedlać język naturalny. Innym czynnikiem może być to, że definicje, reguły czy akty prawne sformułowane są w taki sposób, że prawdopodobieństwo występowania kolejnych słów we frazie jest wysokie. Właśnie ze względu na to, że są to treści dostępne, na których model językowy może się wyuczać oraz kolejność słów i zdań logicznie z siebie wynika.
Jak obsługiwać rozwiązanie JSA?
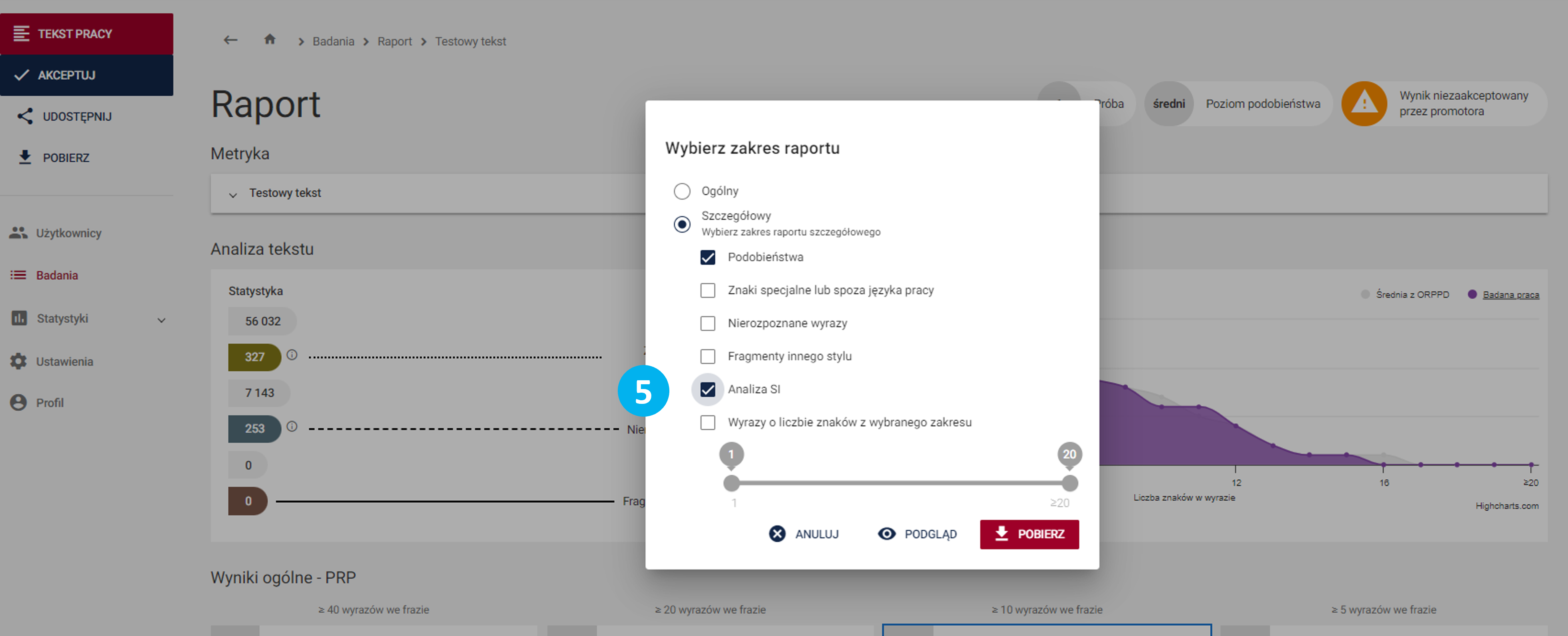
- Podczas zakładania badania należy zaznaczyć checkbox Analiza SI (1). Jest to funkcja dodatkowa.
Określona wartość boxa przy zakładaniu nie może ulec zmianie przy kolejnych próbach – zostaje zablokowana.
Informacja będzie widoczna na metryce badania w każdym miejscu w systemie oraz raporcie *.pdf :
- Po uzyskaniu raportu z badania należy wejść w Tekst pracy (2):
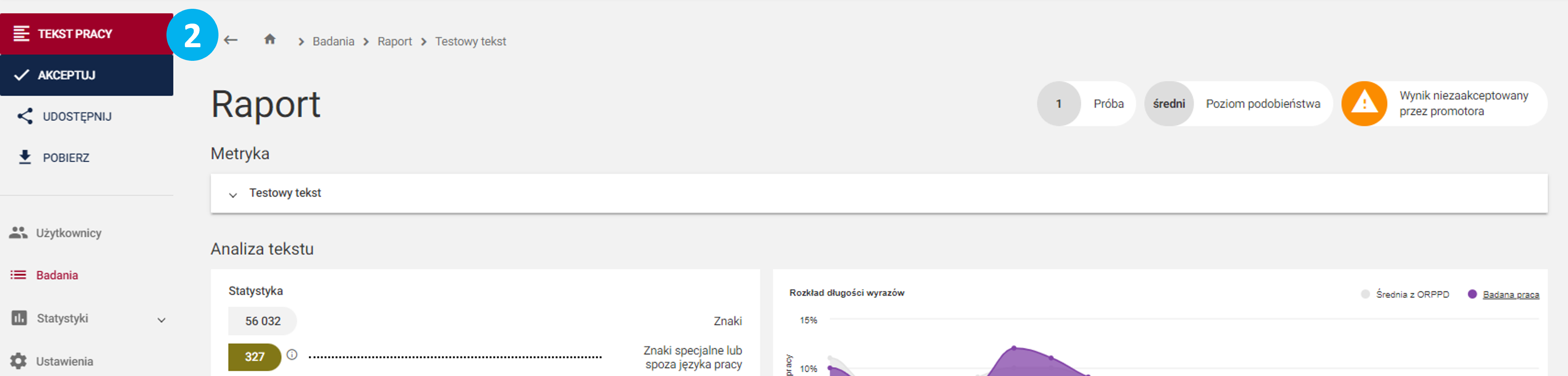
a następnie w zakładkę Analiza SI (3). Wyszukane podejrzane fragmenty (4) będą oznaczone w tekście.
Sekcja ta będzie widoczna tylko jeśli przy zakładaniu badania zaznaczono checkbox.
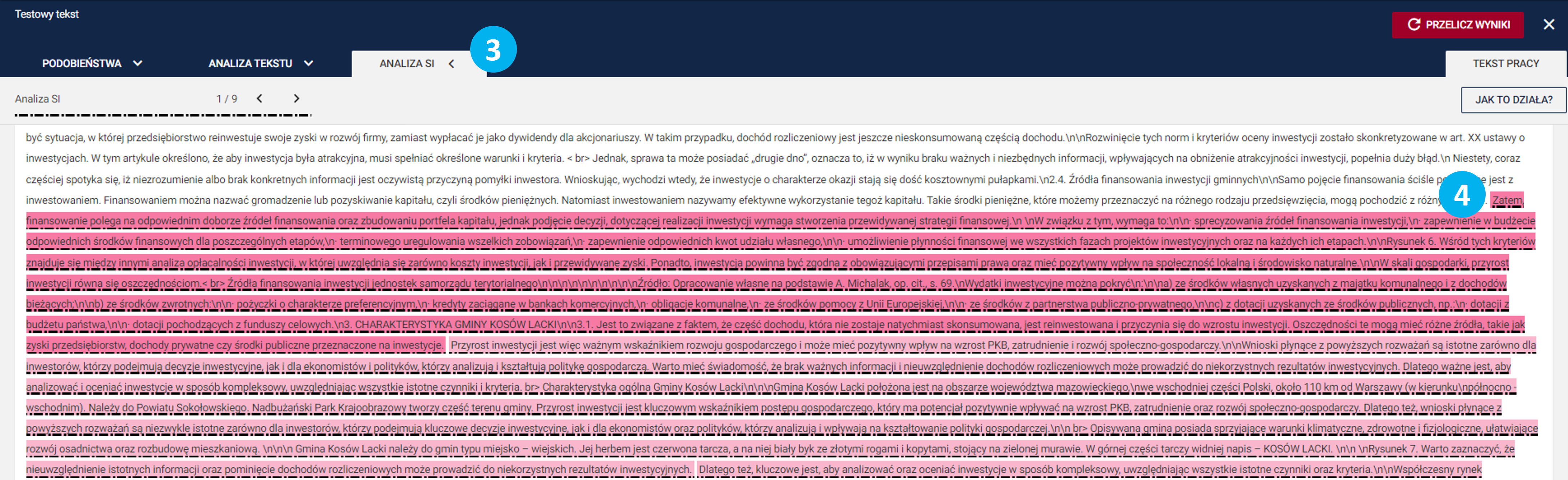
- Podczas wydruku badania można zdefiniować raport w formie szczegółowej, a dla niego wybrać, czy ma obejmować część Analiza SI (5).
Sekcja ta będzie widoczna tylko jeśli przy zakładaniu badania zaznaczono checkbox.