Analiza użycia Sztucznej Inteligencji (SI) wraz z wersją 2.15.0 systemu jest już dostępna w JSA-demo!
Wraz z dynamicznym rozwojem SI autorzy różnych prac coraz chętniej sięgają po narzędzia służące do generowania tekstu. Narzędzia oparte o sztuczną inteligencję są w stanie stworzyć naturalnie brzmiący tekst. Tak ważnym więc staje się możliwość odróżnienia tekstu napisanego przez człowieka od prawdopodobnie wygenerowanego automatycznie.
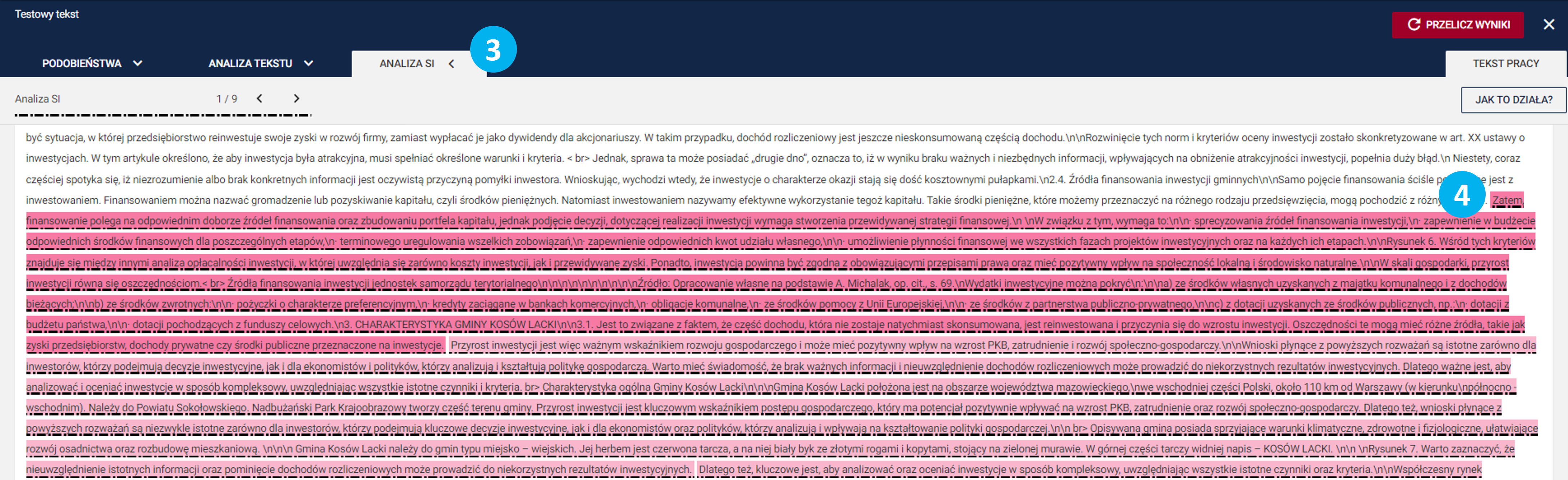
W Państwa ręce oddajemy zatem nową funkcjonalność mającą na celu zidentyfikowanie fragmentów, które prawdopodobnie zostały wygenerowane przez narzędzia korzystające ze sztucznej inteligencji.
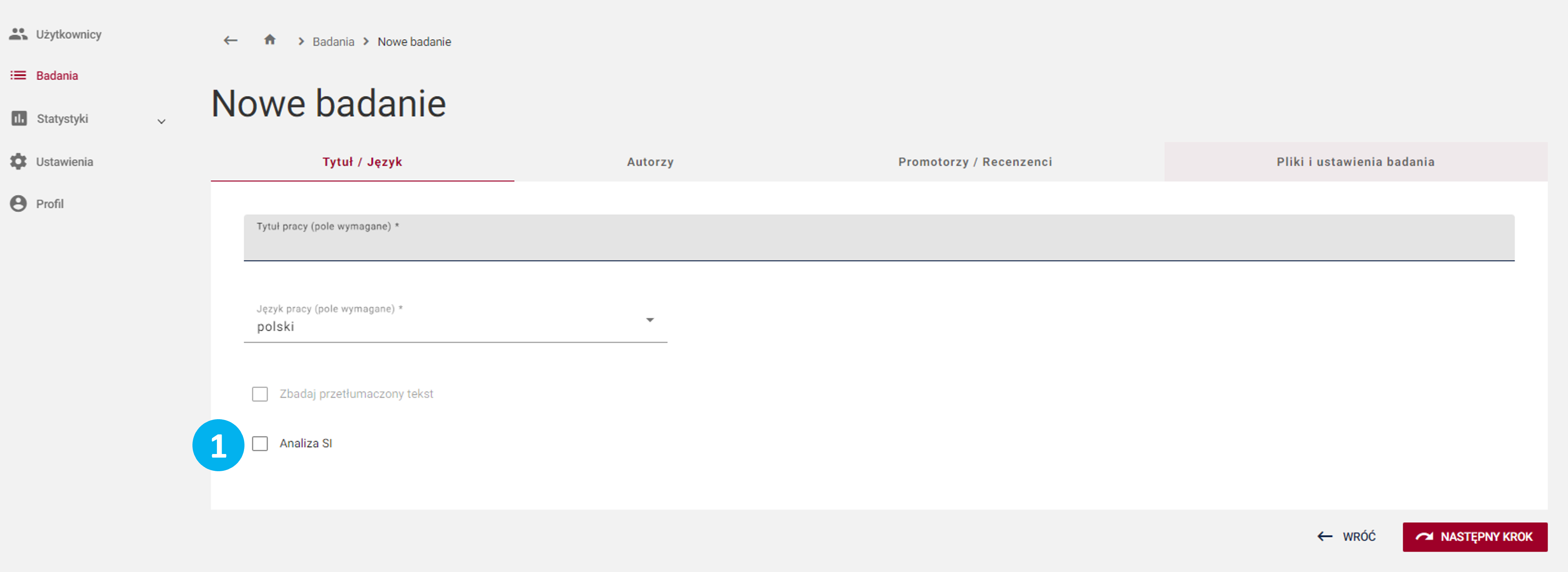
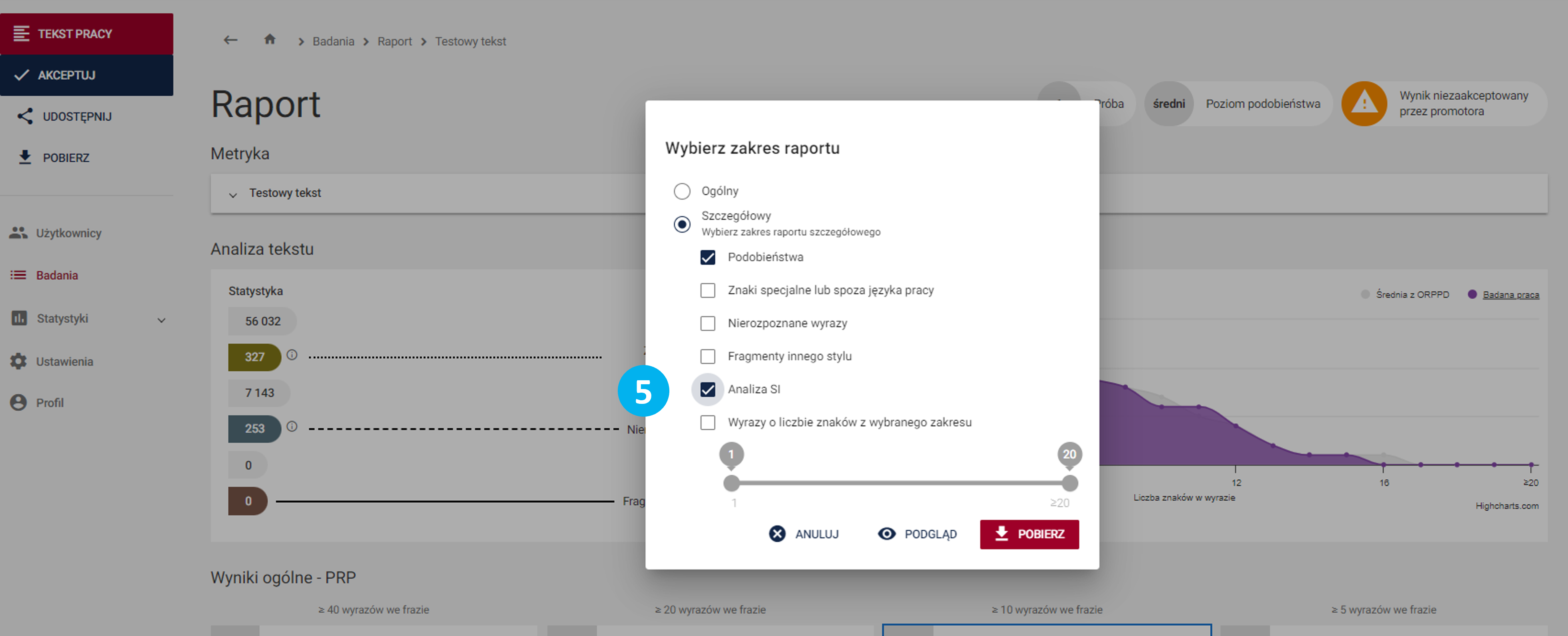
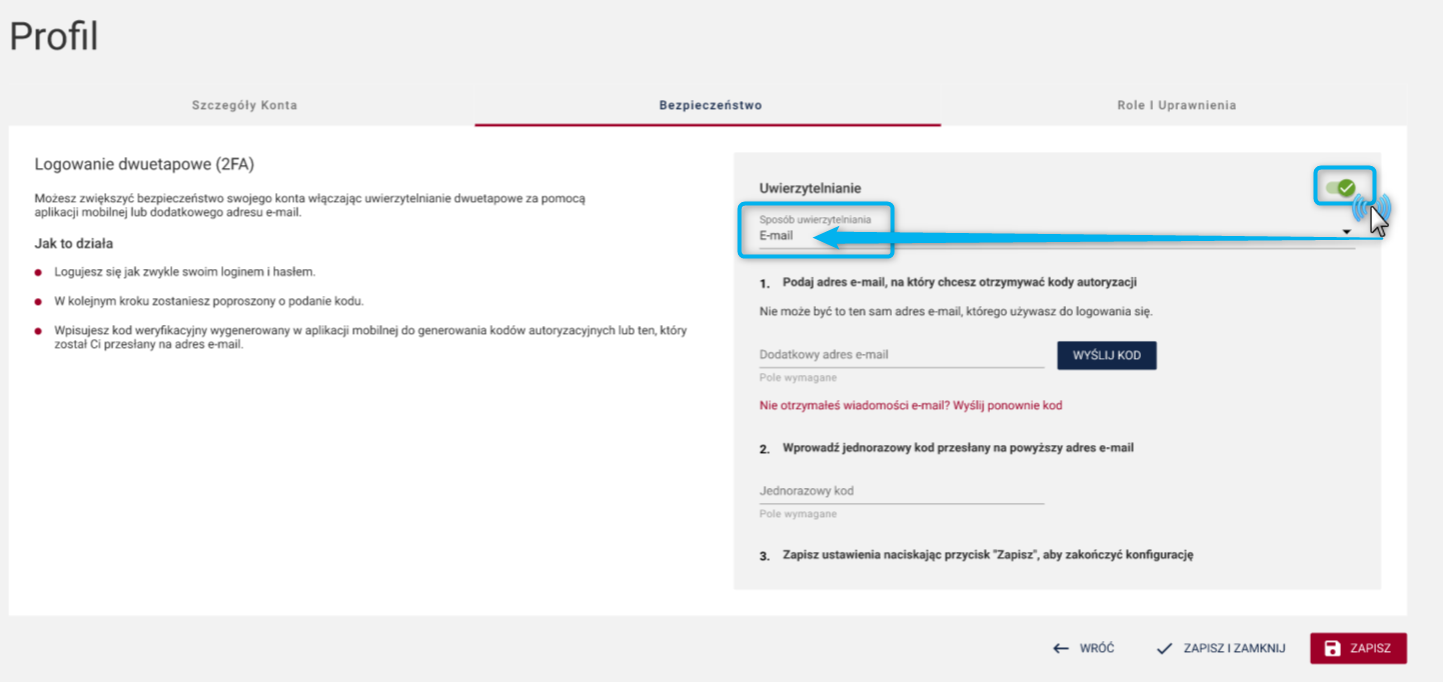
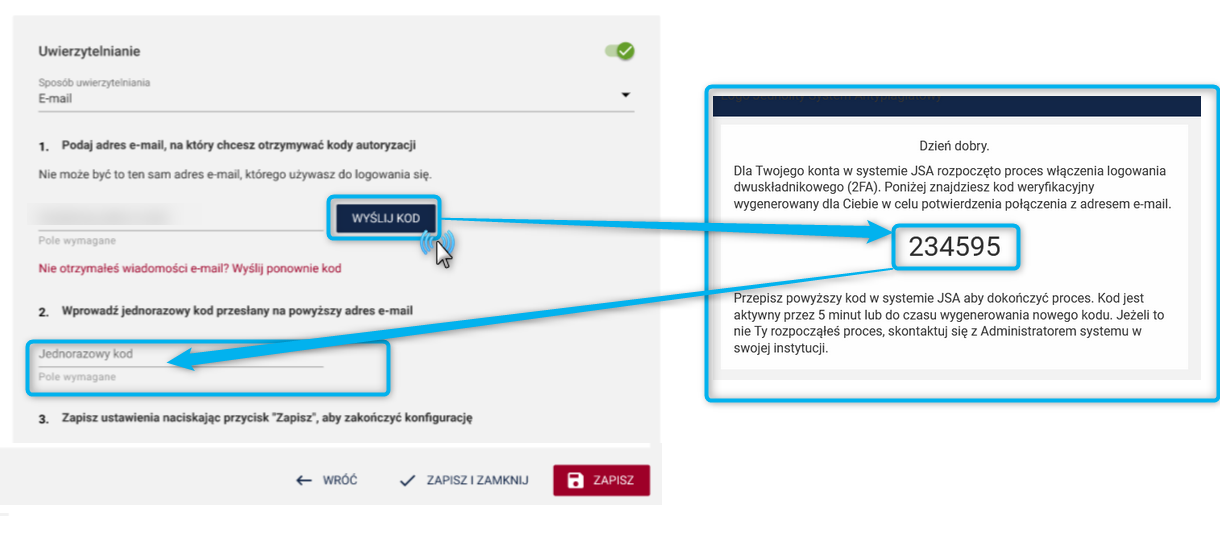
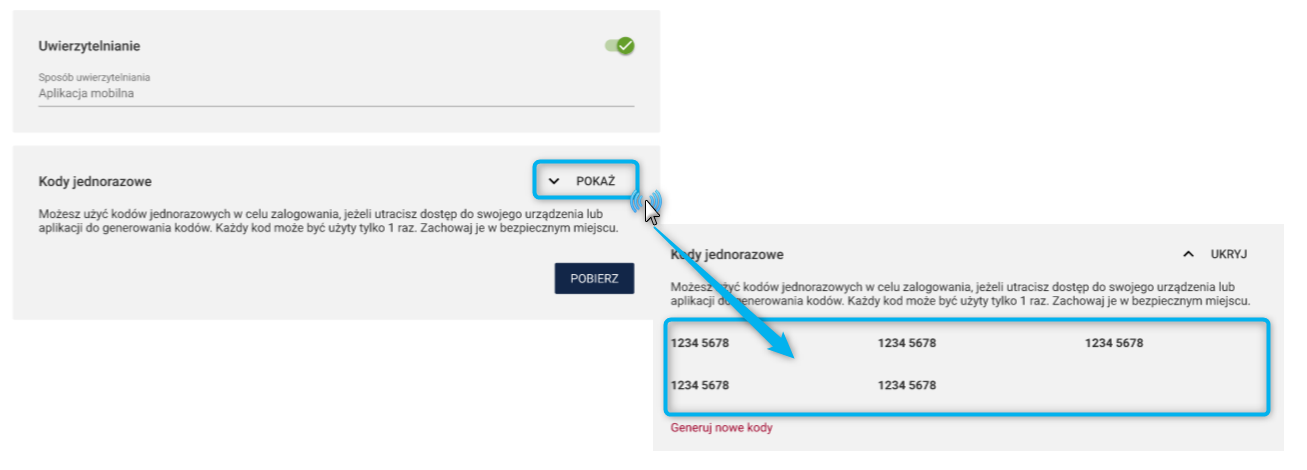
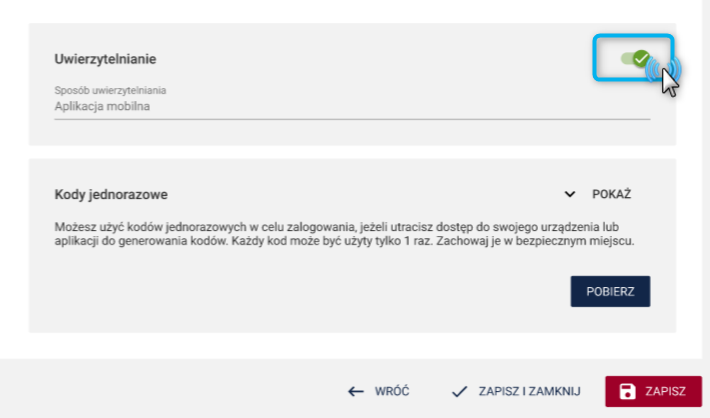
Informujemy jednocześnie, że korzystanie z analizy użycia SI jest nieobowiązkowe i obejmuje tylko takie badania, dla których przy zakładaniu metryki zdefiniowano odpowiednią opcję.
Nowa funkcjonalność, w związku ze zmianami w zakresie REST API pozostanie na środowisku testowym przez co najmniej 2 tygodnie.
Więcej informacji na temat funkcjonalności tutaj.