W dniu 15.05.2020r. zaktualizowano system do wersji v2.0.1 Aktualizacja wyeliminowała błędy dla instytucji bezwydziałowych w zw. z integracją z POL-on2.
Prosimy pamiętać, aby odświeżyć okno przeglądarki po aktualizacji systemu (zalecamy naciśnięcie klawiszy klawiatury CTRL+F5 lub dla CMD+R).
Archiwum autora
Wersja systemu v2.0.0 na środowisku produkcyjnym-Integracja POLon2
Szanowni Państwo, w dniu 14.05.2020 wdrożono na środowisko produkcyjne nową wersję systemu v2.0.0, która wprowadza integrację danych z POLon2.
Zaktualizowanie integracji było niezbędne aby dwa systemy JSA i POLon2 mogły nadal działać używając tych samych danych. Nowa architektura POLon2 fundamentalnie zmieniła identyfikację obiektów w JSA. Zmiany dotyczą interfejsu użytkownika jak i w API. Wszystkie zmiany zostały opisane na stronach pomocy, gdzie dostępna jest również nowa dokumentacja API.
Prosimy pamiętać, aby odświeżyć okno przeglądarki po aktualizacji systemu (zalecamy naciśnięcie klawiszy klawiatury CTRL+F5 lub dla CMD+R).
Nowa wersja systemu v1.3.8
W dniu 24.04.2020r. zaktualizowano system do wersji v1.3.8, która obejmowała poprawienie wyświetlania przycisków w oknie Tekstu pracy dla wersji anglojęzycznej systemu, poprawienie logiki sortowania użytkowników po dacie dodania do instytucji, naprawienie błędu wyświetlania pełnej listy użytkowników dla administratorów wydziałowych.
Prosimy pamiętać, aby odświeżyć okno przeglądarki po aktualizacji systemu (zalecamy naciśnięcie klawiszy klawiatury CTRL+F5 lub dla CMD+R).
Nowa wersja systemu v1.3.7
W dniu 09.04.2020r. zaktualizowano system do wersji v1.3.7 Aktualizacja obejmowała: optymalizację widoku Raportu (szczegóły w aktualności), optymalizację widoku Badań (szczegóły w aktualności), inne zmiany frontend wyświetlania profilu oraz listy użytkowników, wyeliminowanie błędu automatycznego wylogowania z JSA bez komunikatu o zbliżającym się końcu sesji, naprawienie błędu niewyłączających się komunikatów.
Prosimy pamiętać, aby odświeżyć okno przeglądarki po aktualizacji systemu (zalecamy naciśnięcie klawiszy klawiatury CTRL+F5 lub dla CMD+R).
Nowa wersja systemu v1.3.6
W dniu 02.04.2020r. zaktualizowano system do wersji v1.3.6 tym samym aktualizując regulamin korzystania z systemu JSA oraz publikując deklarację dostępności systemu JSA (zgodność z wymogami WCAG).
Prosimy pamiętać, aby odświeżyć okno przeglądarki po aktualizacji systemu (zalecamy naciśnięcie klawiszy klawiatury CTRL+F5 lub dla CMD+R).
Aktualizacja v1.3.5 na środowisku produkcyjnym. Harmonogram prac integracji z POL-on 2.0
W dniu 09.03.2020r. wdrożono na środowisko produkcyjne wersję systemu v1.3.5. Zmiany dotyczą zakładania nowego badania dla studenta jedynie z kierunku wprowadzonego w POL-on 2.0. Informujemy również, związku z pracami trwającymi w systemie POL-on, że został ustalony harmonogram integracji z systemem JSA mający na celu finalne dostosowanie jego działania do pracy na danych POL-on 2.0
W związku z wdrożeniem nowej wersji systemu prosimy pamiętać, aby odświeżyć okno przeglądarki po aktualizacji systemu (zalecamy naciśnięcie klawiszy klawiatury CTRL+F5 lub dla CMD+R).
Wersja systemu v1.3.5 dla kierunków z POL-on 2.0. (zmiany API na środowisku testowym)
W dniu 06.03.2020r. zaktualizowano system do wersji v1.3.5 (środowisko testowe). Aktualizacja obejmowała zmiany przy zakładaniu nowego badania dla studenta z kierunku wprowadzonego w POL-on 2.0. Dla interfejsu użytkownika: w sekcji Autorzy dopuszczalne jest wprowadzenie ręcznie wartości dla pola Kierunek. Dla systemów zintegrowanych przez API: należy przesłać puste wartości pól studyUid oraz studentUid i uzupełnić pola study oraz firstName i lastName dla autora. Więcej szczegółów w Aktualnościach.
Prosimy pamiętać, aby odświeżyć okno przeglądarki po aktualizacji systemu (zalecamy naciśnięcie klawiszy klawiatury CTRL+F5 lub dla CMD+R).
Nowa wersja systemu v1.3.4 oraz zmiany API na środowisku produkcyjnym
W dniu 21.02.2020r. zaktualizowano system do wersji v1.3.4 Aktualizacja obejmowała dodanie sekcji wniosków do widoku raportu (interfejs użytkownika, więcej znaleźć można tutaj), poprawę obsługi tekstów wykluczonych przez instytucje, wyeliminowanie błędu, przez który użytkownik bez ról nie był widoczny na liście użytkowników, poprawkę do parsowania plików pdf, poprawę wyświetlania badań na liście badań, poprawki dostosowujące system do wymagań zw. z dostępnością WCAG, korektę opisu uprawnień, dodanie strony błędu 404.
Jednocześnie informujemy, że na środowisko produkcyjne zostały wdrożone zmiany dla integracji API JSA (od 20.11.2019 na środowisku testowym) obejmujące umożliwienie połączenia zwrotnego JSA – system uczelniany w przypadku zmian statusu badania (np. po Akceptacji badania za pośrednictwem interfejsu) oraz umożliwienie pobrania raportu w języku angielskim.
Prosimy pamiętać, aby odświeżyć okno przeglądarki po aktualizacji systemu (zalecamy naciśnięcie klawiszy klawiatury CTRL+F5 lub dla CMD+R).
Zmiany API na środowisku testowym
Informujemy, że na środowisko testowe wprowadzono zmiany dla integracji API JSA. Odpowiednio zaktualizowaną dokumentację znajdą Państwo na stronie dokumentacji API.
Zmiany obejmują umożliwienie połączenia zwrotnego JSA – system uczelniany w przypadku zmian statusu badania (np. po Akceptacji badania za pośrednictwem interfejsu) oraz umożliwienie pobrania raportu w języku angielskim. Przypominamy, że zgodnie z przyjętym założeniem, zmiany dla integracji wprowadzane są na środowisko demo na okres 2 tygodni w celu umożliwienia odbiorcom dostosowania swoich systemó
Aktualizacja systemu v1.3.3
W dniu 28.01.2020r. zaktualizowano system do wersji v1.3.3 Aktualizacja miała na celu naprawienie błędu wyliczania nadmiarowego PRP.
Prosimy pamiętać, aby odświeżyć okno przeglądarki po aktualizacji systemu (zalecamy naciśnięcie klawiszy klawiatury CTRL+F5 lub dla CMD+R).
Aktualizacja systemu v1.3.2 fix
W dniu 27.01.2020r. zaktualizowano system do wersji v1.3.2 fix Aktualizacja miała na celu naprawienie błędu API zwracającego wartość null w polu general oraz poprawka dla badań kończących się statusem Błąd.
Prosimy pamiętać, aby odświeżyć okno przeglądarki po aktualizacji systemu (zalecamy naciśnięcie klawiszy klawiatury CTRL+F5 lub dla CMD+R).
Nowa wersja systemu v1.3.2
W dniu 23.01.2020r. zaktualizowano system do wersji v1.3.2 uwzględniającej oznaczenie wykluczeń instytucji/jednostki na raportach pdf, dodanie komunikatu przy próbie założenia nowej próby badania po zmianie ustawień przez Administratora (dotychczas obsługiwane poprzez ukrycie przycisku nowej próby), przetłumaczenie wydruków raportu z badania na język angielski, przetłumaczenie komunikatów dla wersji angielskiej interfejsu, poprawienie etykiety dla cytowań/kopii na raportach pdf, uzupełnienie listy eksportu użytkowników o stopień/tytuł, naprawienie błędu dla pracy z nieunikalnymi autorami oraz inne drobne poprawki.
Prosimy pamiętać, aby odświeżyć okno przeglądarki po aktualizacji systemu (zalecamy naciśnięcie klawiszy klawiatury CTRL+F5 lub dla CMD+R).
Nowa wersja systemu v1.3.1
W dniu 23.12.2019r. zaktualizowano system do wersji v1.3.1 Nowa wersja systemu obejmuje wprowadzenie priorytetyzacji znalezionych fragmentów podobieństw.
Prosimy pamiętać, aby odświeżyć okno przeglądarki po aktualizacji systemu (zalecamy naciśnięcie klawiszy klawiatury CTRL+F5 lub dla CMD+R).
Białe znaki
Białe znaki to manipulacje, które polegają na wprowadzeniu do tekstu pomiędzy literami lub wyrazami dodatkowych liter lub znaków, którym nadaje się biały kolor czcionki. Znaki takie nie są widoczne w formie wydruku np.:
an%a%lo%gi%czni%e %do %te%g%o %st%wie%r%dze%ni%a %mo%ż%na %uz%na%ć, %że %je%g%o %za%mi%ar%y
Manipulacje takie mają na celu ukrycie nieprawnie użytych fragmentów tekstu źródłowego. Białe znaki można śledzić w analizie tekstu zarówno poprzez funkcję Nierozpoznane wyrazy jak i Długość wyrazów w badanej pracy (dla zwiększonej długości wyrazów).
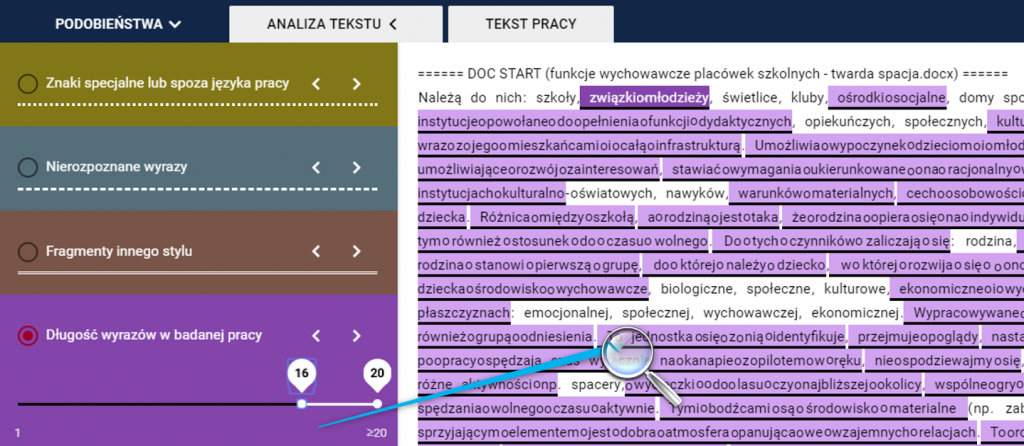
Mikrospacje
Mikrospacje są to manipulacje polegające na wstawieniu dodatkowych, pomniejszonych spacji w jeden wyraz pomiędzy literami, co w powiększeniu wygląda np. tak:
an a lo gi czni e do te g o st wie r dze ni a mo ż na uz na ć, że je g o za mi ar y
Manipulacje takie mają na celu ukrycie nieprawnie użytych fragmentów tekstu źródłowego. Mikrospacje można śledzić w widoku analizy tekstu przy funkcji Nierozpoznanych wyrazów.
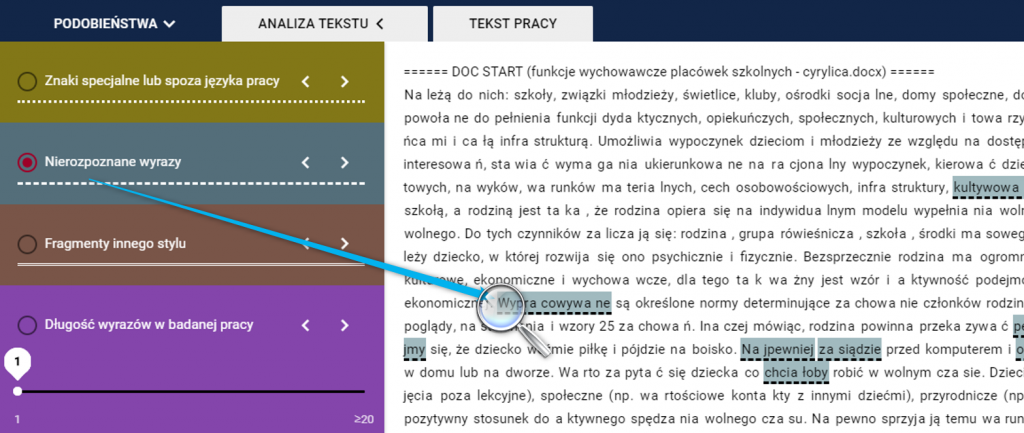
Cytat
Cytat lub kopia to oznaczenie fragmentu tekstu, który jest identyczny z tekstem źródłowym.
Należy pamiętać, że taki fragment może być zarówno prawidłowym cytowaniem jak i kopią źródła.
Nowa wersja systemu v1.3.0 (Poziom podobieństwa i oznaczenie cytowań lub kopii)
W dniu 20.12.2019r. zaktualizowano system do wersji v1.3.0, w której zmieniono dotychczasowy parametr „siły podobieństwa tekstu”, wprowadzono nowy parametr „Poziom podobieństwa” (zachęcamy do zapoznania się z funkcjonowaniem parametru na stronach Centrum Pomocy), dodano oznaczanie możliwych cytowań lub kopii w tekście pracy, oraz pozostałe zmiany: wprowadzenie eksportu listy użytkowników, poprawki wyglądu i budowy wydruku raportu pdf, dodanie sekcji „Uwagi” do wydruków raportu pdf, naprawienie błędu występującego przy anulowaniu pobierania raportu pdf, uzupełnienie wersji anglojęzycznej, naprawienie funkcjonowania przycisku [Wróć] w przypadku uprzedniego przefiltrowania listy badań lub użytkowników, alfabetyczne sortowanie instytucji w wyborze kontekstu podczas logowania użytkownika, dodanie komunikatu błędu dla wykorzystanego linku aktywacyjnego, dodanie spinera w module Statystyk przy przeładowaniu danych, inne drobne poprawki frontend.
Prosimy pamiętać, aby odświeżyć okno przeglądarki po aktualizacji systemu (zalecamy naciśnięcie klawiszy klawiatury CTRL+F5 lub dla CMD+R).
Możliwe prawidłowe cytowania lub kopie
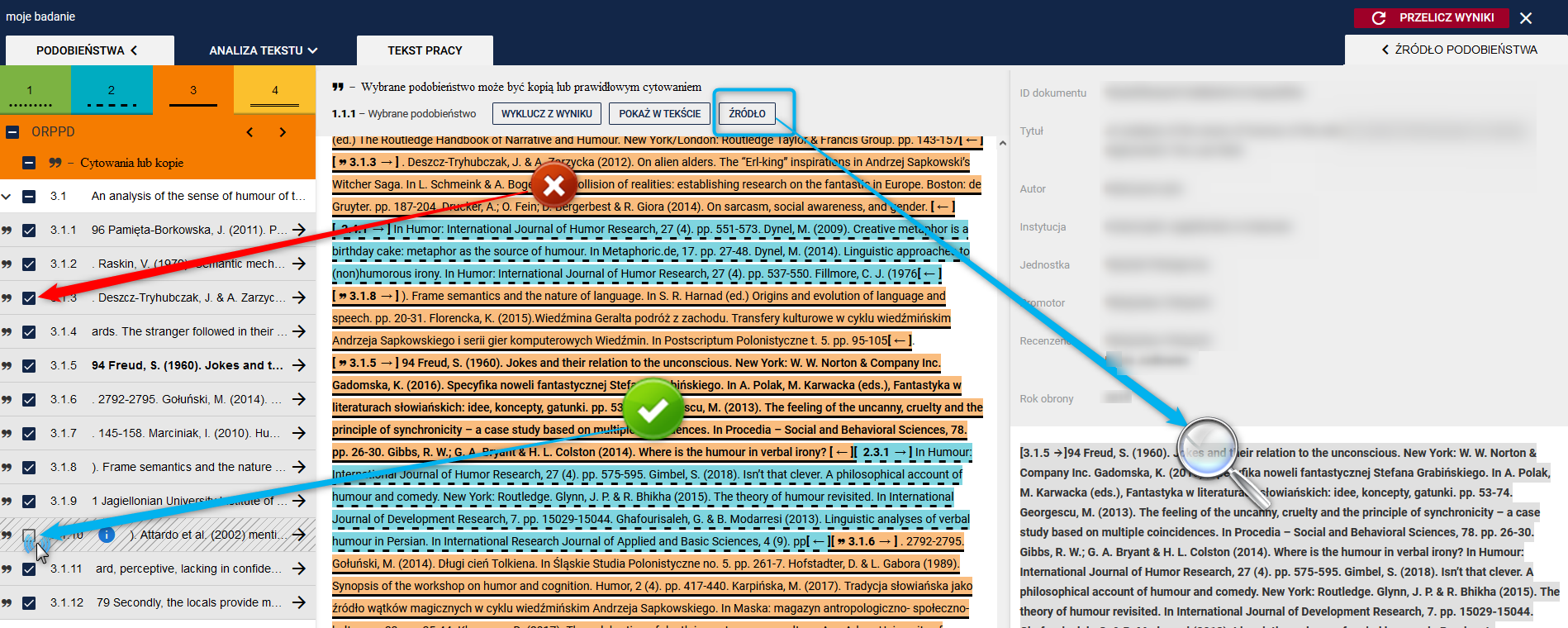
System umożliwia rozpoznanie fragmentów pracy, które są identyczne lub niemal identyczne do treści źródłowej. Oznacza to tyle, że fragment może być zarówno prawidłowo zastosowanym przez autora cytowaniem lub niezmienioną kopią treści ze źródła. Dlatego też istotne jest to, aby fragmentom tym przyjrzeć się w pierwszej kolejności.
Cytaty lub kopie oznaczane są symbole cudzysłowu zarówno w treści pracy jak i na liście podobieństw. Dodatkowo, na szarym pasku funkcyjnym umieszczony jest komunikat przypominający.
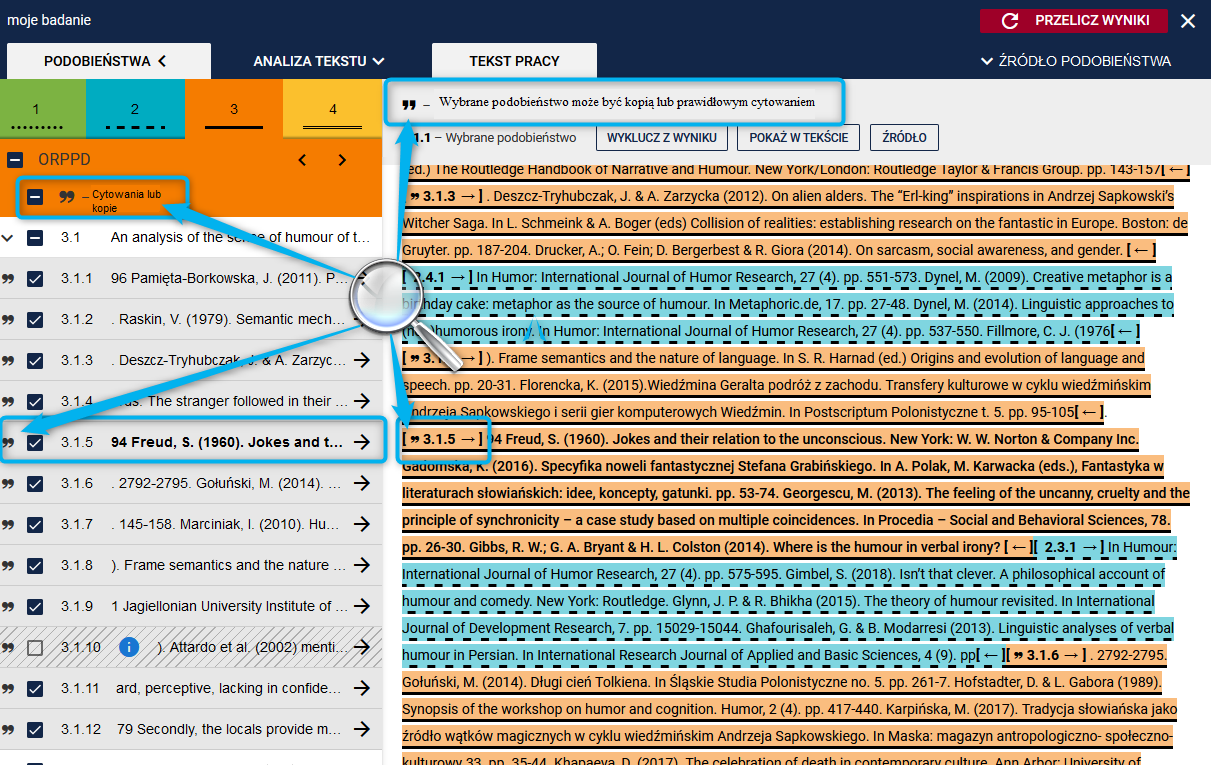
Zalecane jest, aby sprawdzanie merytorycznej poprawności oznaczonych fragmentów rozpocząć od porównania ich treści ze źródłem podobieństwa, tak, aby upewnić co do poprawności lub bezzasadności użycia źródła.
Jeżeli Promotor uznaje fragment za prawidłowo zacytowany może wykluczyć go z wyniku odznaczając na liście podobieństw (jak pokazuje zdjęcie poniżej). Natomiast jeżeli tekst jest nieprawnie zaczerpnięty do pracy wtedy należy pozostawić go zaznaczonym.
Parametr „Poziom podobieństwa”
Poziom podobieństwa jest to parametr dostępny dla Administratorów systemu w zakładce Ustawienia – Parametry wyniku.
Funkcjonalność ta wpływa na wrażliwość algorytmu detekcji na zbieżność tekstów. Służy do dokładnego określenia przez jednostkę czy i w jakim stopniu system ma wskazywać fragmenty będące sparafrazowanym odpowiednikiem znalezionego źródła. Dlatego też skala, na jakiej można zmieniać wartość jest czterostopniowa, a poziom można ustawić na: niski (wartość rekomendowana), średni, wysoki oraz bardzo wysoki.
Parametr ten nie wpływa na algorytm detekcji. System określa wskazania fragmentów w trakcie badania, zaś zmiany parametru wpływają na to, czy jednostka chce zobaczyć je wszystkie.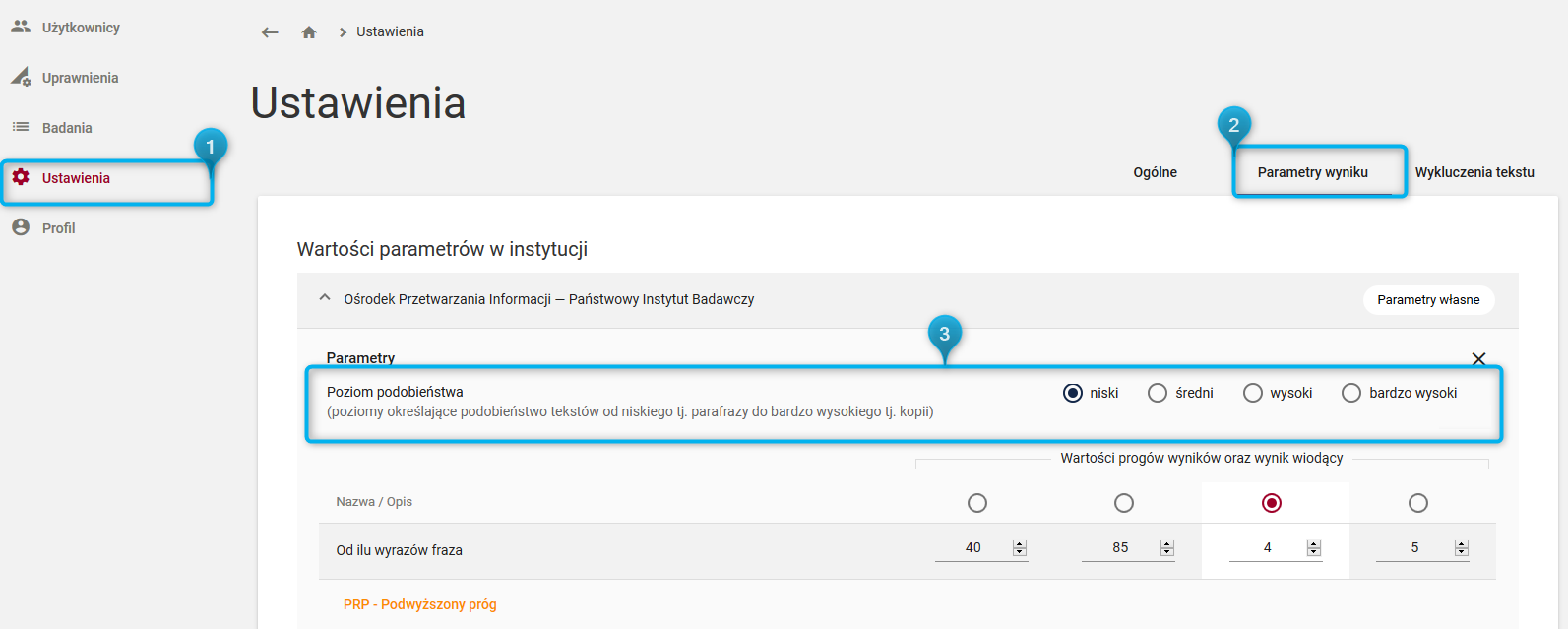
Wartość parametru niski, w kontekście powyższego, odnosi się do tego, czy fragment wskazywany przez system posiada na tyle niski stopień podobieństwa z fragmentem źródłowym, aby można go było określić mianem parafrazy, a przy tym wykazuje podobieństwo na tyle istotne, by uznać go za podobny i możliwie zaczerpnięty z tekstu źródłowego. Wartość ta jest rekomendowana ze względu na większe prawdopodobieństwo wykrycia plagiatu, który uwzględnia świadome zmiany tekstu czy różnicowanie stylów.
Kolejna wartość parametru: średni koryguje wskazania fragmentów przez system w ten sposób, że jest mniej wyczulony na parafrazy tekstu niż poziom niski. A zatem, jeżeli w tym samym fragmencie tekstu jego początek i koniec są bardziej zmodyfikowane (parafraza, przestawny szyk, dodane wyrazy) to części te nie zostaną wykazane w badaniu. Wynik uwzględniać będzie tylko te części fragmentów, które są nieco bardziej zbliżone do kopii.
Wysoki poziom ma służyć dalszemu odsianiu fragmentów podobnych, których podobieństwo do kopii jest zdecydowanie widoczne, jednak wciąż dopuszcza w niewielkim stopniu różnice w porównaniu do tekstu źródłowego.
Ostatnia wartość parametru tj. bardzo wysoki poziom podobieństwa modyfikuje wskazania fragmentów w ten sposób, iż pomija znalezione fragmenty zawierające parafrazy i inne modyfikacje lingwistyczne (pomimo ich ewentualnego znalezienia w trakcie badania), tym samym prezentując w raporcie tylko takie fragmenty, które są idealną kopią lub zawierają minimalne różnice względem tekstu źródłowego.
Grafika poniżej ma na celu orientacyjne wyjaśnienie zagadnienia:
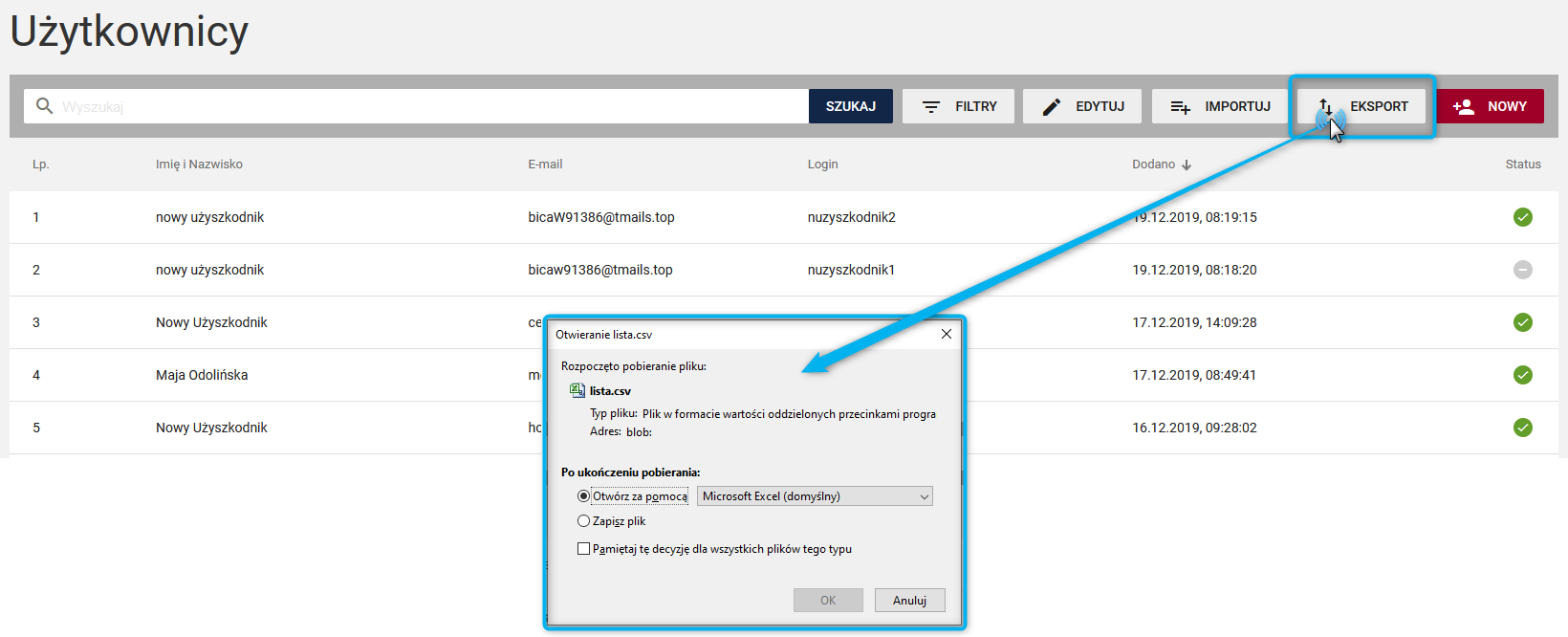
Eksport listy użytkowników
System umożliwia wyeksportowanie listy kont użytkowników założonych w kontekście jednostki zalogowanego Administratora.
W tym celu należy na pasku funkcyjnym ponad listą użytkowników w zakładce Użytkownicy. Na ekranie pojawi się okno systemowe zapisu pliku. Lista pobierana jest do pliku csv.
Istnieje również możliwość wyeksportowania wybranej grupy użytkowników z listy.
Aby to zrobić należy rozwinąć formularz z filtrami, nanieść odpowiednie filtry na listę użytkowników, a następnie wyeksportować powstałą w ten sposób listę.
